论文链接:https://arxiv.org/pdf/2207.14255
代码链接:
摘要
我们证明,在对数据集进行简单的转换(即简单地将一段文本从文档中间移到末尾)后,自回归语言模型可以学习填充文本。虽然这种数据增强近年来引起了广泛关注,但我们提供了大量证据表明,使用大量以这种方式转换的数据来训练模型,不会损害其原有的从左到右的生成能力,这一点已通过困惑度和在广泛尺度上的采样评估来衡量。鉴于训练模型进行中间填充 (FIM) 的实用性、简便性和效率,我们建议未来的自回归语言模型默认使用 FIM 进行训练。为此,我们对关键超参数(例如数据转换频率、转换结构以及填充跨度的选择方法)进行了一系列消融。我们使用这些消融来规定训练 FIM 模型的强大默认设置和最佳实践。我们已经在 API 中发布了使用最佳实践训练的最佳填充模型,并发布了填充基准测试以支持未来的研究。
1.Introduction
自 Transformer 推出以来,基于各种互联网规模数据集训练的大语言模型 (LLM) 取得了显著成功。这些模型能够根据自然语言提示生成连贯且合理的补全,并在阅读理解、问答、逻辑推理和常识推理等多项基准测试中取得了最佳性能。
基于 Transformer 的语言模型大致可分为几类:像 BERT 这样的 encoder-only 模型通常使用 MASK 语言建模目标进行训练,而像 T5 这样的 encoder-decoder 模型通常使用跨度预测目标进行训练。最后,像 GPT 模型系列这样的基于因果解码器的语言模型则使用从左到右的下一个 token 预测目标进行训练。当今规模最大、能力最强的生成式语言模型,例如 GPT-3、Codex、LaMDA、GLaM、PaLM、Gopher、Jurassic-1 和 Chinchilla,都属于后一类模型。基于因果解码器的模型在最大规模上之所以如此受欢迎,是因为它们在开放式文本生成、上下文学习(使用少样本启动)、预训练计算效率以及一定程度上在成功扩展方面的历史先例方面都表现出色。这些模型在架构上也更简单,并且通常无需针对特定任务进行微调即可更高效,这使得它们在推理和部署方面更具吸引力。
所有模型类别在填充方面都存在局限性。填充是指模型的任务是在提示中的特定位置生成文本,同时以前缀和后缀作为条件。从左到右模型只能以前缀作为条件。虽然纯编码器模型和编码器-解码器模型能够以后缀作为条件,但在训练时看到的填充区域长度通常比实际需要的长度短得多。这很遗憾,因为填充通常出现在生成点前后都存在上下文的应用中。例如,在创建编码助手时,填充可用于生成文档字符串、生成导入语句或完成未完成的函数。
我们本研究的目标是通过为基于因果解码器的语言模型(目前是大规模语言建模中最主要的范式)添加中间填充 (FIM) 功能来解决这一限制。我们证明,只需对训练数据进行简单的修改,且无需更改模型架构,基于因果解码器的自回归 (AR) 语言模型就可以学习中间填充,而不会损害其正常的从左到右的生成能力。
我们的方法的关键(如第 3 节所述)是对数据集的一小部分进行转换,我们将文档随机分成三部分,并将中间部分移动到末尾:
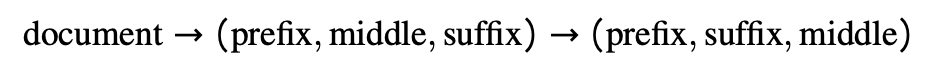
然后,我们使用特殊 token 将这三个部分连接起来。这与 [Donahue et al., 2020, Aghajanyan et al., 2022, Fried et al., 2022] 中使用的过程类似。
与先前的研究相比,我们的研究更注重训练 FIM 模型的计算效率。鉴于人们对训练大语言模型的兴趣日益浓厚,这一点尤为重要。大语言模型的训练成本高昂,且能耗巨大。通常,在为语言模型添加新的目标或功能时,我们认为最关键的问题是其对现有功能的影响以及计算效率的权衡。
与大多数在多个目标和数据集上联合训练的情况不同,我们证明了在 FIM 变换数据和普通从左到右数据混合上联合训练的模型,在学习如何填充中间内容的同时,实现了相同的从左到右能力。我们称之为“FIM-for-free 属性”。
下文中,我们使用术语“FIM 模型”来指代任何基于 FIM 变换数据和正常从左到右数据混合训练的模型。我们将未使用任何 FIM 数据(即 FIM 率为 0%)训练的模型称为 AR 模型。
1.1 Our contributions

本文的主要贡献如下:
- FIM-for-free property。我们通过训练一组包含 8 个模型(分别包含和不包含 FIM)进行了一项广泛的扩展研究,结果表明,FIM 可以在不损害预训练中从左到右能力的情况下进行学习。我们利用困惑度和基于采样的基准,从代码和语言两个角度验证了这一结论。
- Best practices for FIM in pretraining。我们阐明了使用综合消融训练 FIM 模型相关的许多超参数的影响。具体来说,我们研究了 FIM 率(将 FIM 变换应用于数据的概率)、FIM 变换的不同变体以及中间跨度的选择。
- Finetuning inefficiency。除了从头开始训练 FIM 模型外,另一种方法是通过微调现有语言模型来学习此功能。我们证明,使用 FIM 进行微调在计算上效率低下。虽然在预训练期间可以免费学习 FIM,但在微调期间学习 FIM 需要大量额外的计算才能达到与预训练类似的性能水平。
- New infilling benchmarks。为了研究我们模型的生成能力,我们需要评估自由格式生成样本的正确性。为此,我们专注于可以使用单元测试来评估长 FIM 样本正确性的代码。具体来说,我们使用 [Fried et al., 2022] 引入的单行和多行填充基准,通过删除 HumanEval 规范解中的非空行来实现。然而,由于基于行的评估无法涵盖 FIM 的所有用例,我们创建了两个新的基准,分别称为随机跨度填充和随机跨度轻量填充。我们将在第 2 部分更全面地讨论这些基准和我们的评估方法。
- Need for sampling evaluations。在 4.2、4.4 节和附录 B 中,我们发现,在 FIM 训练中更改各种超参数通常会导致 FIM 测试损失的差异微乎其微,但基于采样的基准测试却存在巨大差异。采样基准测试不仅更接近实际用例,而且似乎能够区分出使用测试损失可能遗漏的收益。这是一个重要的发现,因为缩放定律分析通常仅依赖于测试损失,而我们发现,如果不结合其他评估方法,测试损失会产生误导。
对比上面的第一点和第三点很有趣。第一点指出,在预训练中学习 FIM 是免费的,而将其留给微调则成本高得惊人。我们将在第 6 节中讨论这一发现的潜在解释。为了建立 FIM-for-free 属性,我们对各种规模的代码和语言进行了消融研究。我们训练了 8 个模型,参数从 50M 到 69B,有的带 FIM,有的不带 FIM,并在各种自回归基准上比较了它们的性能。具体来说,我们用 100B 个 token 在代码上训练了 16 个模型,用 100B 个 token 在自然语言上训练了另外 16 个模型。图 1 展示了这些模型在正常自回归从左到右语言建模测试损失方面的比较。在这两个领域,FIM 模型都实现了与非 FIM 模型相似的 AR 测试损失。
在第 4 节中,我们通过在非损失函数基准测试上比较 FIM 和 AR 模型,为 FIM-for-free 特性提供了更多证据。此外,我们在 4.2 节中看到,FIM-for-free 特性存在一种更强的形式。FIM 训练不仅在最终检查点上不会对自回归能力造成影响,而且在整个训练过程中也不会受到影响。图 4 和图 5 中,AR 和 FIM 模型在从左到右损失函数和 HumanEval 评估中匹配的学习曲线证明了这一点。
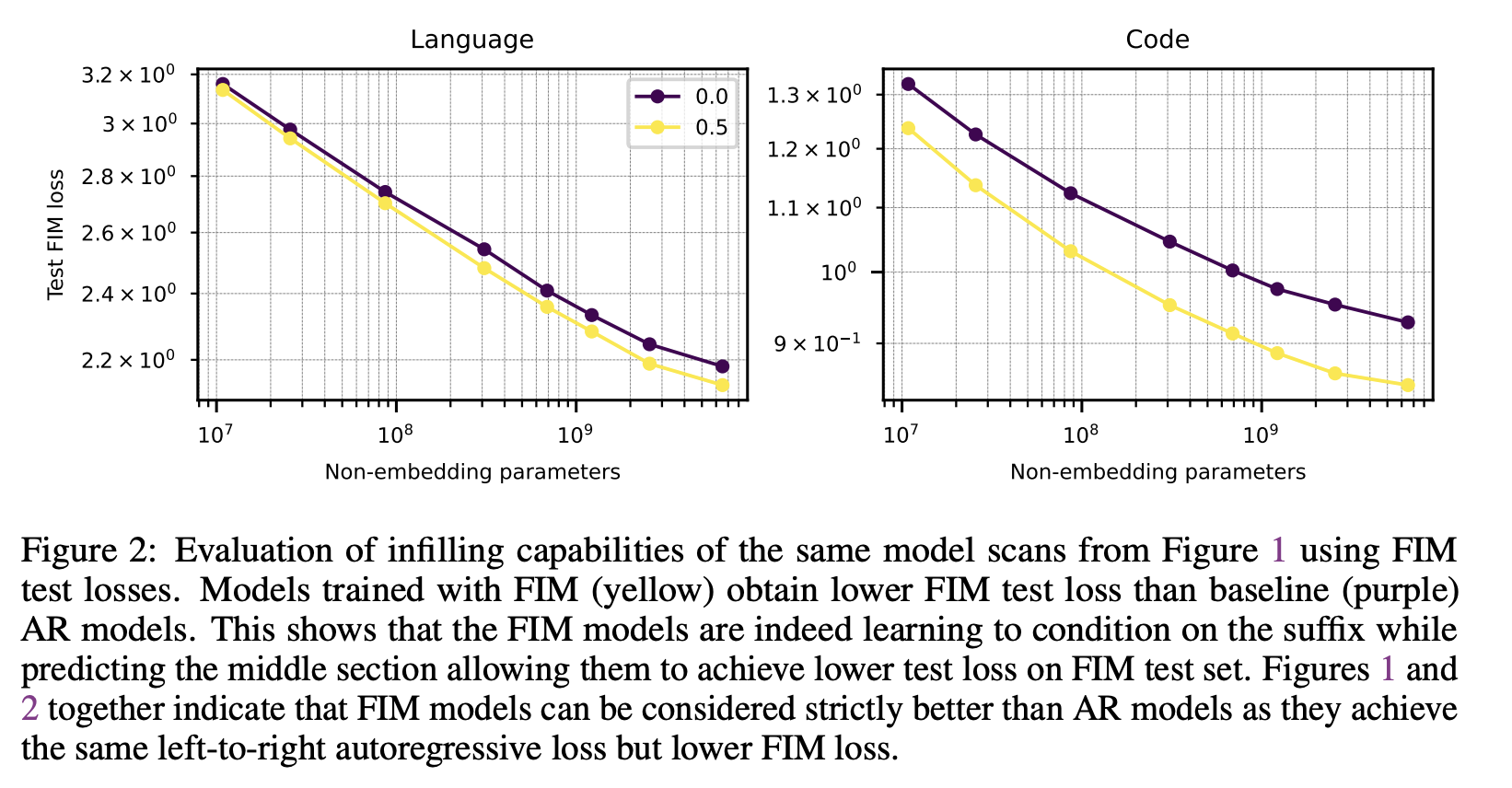
除了研究 FIM 训练对从左到右能力的影响之外,证明模型实际上正在从 FIM 训练中学习填充也很重要。图 2 在 FIM 测试损失的背景下提供了这方面的证据。我们将在第 4 节和附录 H 中更深入地研究模型的填充能力。
2.Evaluation
我们使用 AR 和 FIM 评估基准来分析模型的能力。Vanilla AR 评估对于量化 FIM 训练对从左到右能力的影响非常重要,并且能够让我们证明 1.1 节中提到的 FIM-for-free 特性。FIM 评估对于理解不同超参数对 FIM 训练的影响以及扩展趋势也至关重要。
在本文中,我们交替使用“AR”和 left-to-right 这两个术语。AR 损失指的是正常从左到右数据的交叉熵损失,而 FIM 损失指的是 100% FIM 变换数据的损失。所有测试损失均以每 token 单元的 nats 为单位。在所有基于采样的基准测试中,我们使用核采样,核参数为 0.95。
2.1 Autoregressive evaluation
对于所有领域,我们按典型自回归顺序评估测试损失,以表明即使使用 FIM 增强,学习曲线和扩展趋势也保持不变。除了测试损失之外,我们还在标准基准上进行评估,以证明模型的能力不受 FIM 训练的影响。对于自然语言,我们使用 PIQA、Winograd 和 WinoGrande 进行常识推理,使用 DROP 和 QuAC 进行阅读理解,使用 HellaSwag、LAMBADA 和 StoryCloze 进行完成任务。除 DROP 和 QuAC 外,所有基准均采用少样本提示进行评估。对于代码,我们测量 HumanEval 上的通过率。
2.2 Infilling evaluation
为了创建 FIM 测试,我们将 FIM 变换应用于 FIM 率为 100% 的 AR 测试集中的示例。在 FIM 和 AR 测试集中使用相同的底层示例,可以比较 FIM 和 AR 测试的损失。此外,我们还创建了这些测试集的 MASK 版本,仅测量中间跨度 token 的损失。后一个测试集用于测量 FIM 模型的 P(middle∣prefix,suffix) 和 AR 模型的 P(middle∣prefix),这使我们能够探究 FIM 模型通过对后缀进行条件处理所获得的信息量。
对于生成式填充能力,我们专注于代码,因为我们关注的是自由格式的生成,而不是完形填空式自然语言基准测试中常见的单个或少数 token 的生成。使用代码的优势在于,即使在评估开放式生成的长样本时,我们也可以使用测试套件来评估任务中样本的正确性。
我们使用的所有基于采样的填充基准测试都是通过从 HumanEval 的规范解中移除中间跨度而创建的部分函数补全任务。具体而言,我们使用 [Fried et al., 2022] 提出的单行和多行填充基准测试,其中 HumanEval 规范解中不同跨度的非空行被转换为 FIM 任务。此外,我们还创建了一个名为随机跨度填充的新基准测试,对于每个 HumanEval 问题,我们通过从规范解中均匀随机地选择中间跨度来创建填充任务。下面展示了一个此类任务的示例,其中模型必须预测突出显示的部分(或实现相同目标的替代补全)。更多详细信息,请参阅附录 E。

单行、多行和随机跨度填充共同构成了我们的填充基准测试套件。这些基准测试分别包含 1033、5815 和 1640 个任务。我们注意到,这比原始 HumanEval 数据集中的任务数量(164 个任务)要多得多,这降低了评估中的方差。尽管如此,我们仍然在每个任务中至少采集 100 到 200 个样本,以便在模型最终快照上评估这些基准测试时进一步降低方差。我们还使用了随机跨度填充轻量版(random span infilling light),它是随机跨度填充的较小版本,每个 HumanEval 问题只有一个随机 FIM 任务,总共只有 164 个任务,用于跟踪训练期间的填充能力趋势。
在第 3 部分中,我们发现 FIM 可以通过两种不同的方式准备,分别记为 PSM 和 SPM。为简洁起见,我们仅报告 SPM 填充结果,除非使用 PSM 会改变结论。
3.FIM training and inference
我们对数据集应用随机变换来实现 FIM。我们尝试了两种不同的实现方式:文档级和上下文级。两者的区别在于 FIM 转换发生在数据加载流程的哪个阶段。这种选择很自然,因为长文档可以分解成多个上下文,或者当文档较小时,一个上下文可以包含多个文档。我们首先描述文档级的情况,然后在 3.2 节中描述实现上下文级 FIM 所需的更改。
在文档级 FIM 中,我们以一个称为 FIM rate 的概率 (对于我们的主要模型系列,我们使用 )将每个文档拆分为三部分:前缀、中间部分和后缀。我们在 tokenizer 之前执行此拆分,此时文档仍然是一个字符序列。我们随机均匀地拆分,这意味着前缀、中间部分和后缀的长度预期分别为完整文档的 1/3。
然后,我们分别对这三个部分进行编码,并将特殊 token 添加到每个部分的开头。我们用 、 和 表示这些特殊 token。最后,我们将所有这些部分按前缀、后缀、中间的顺序与其特殊 token 连接起来,形成 FIM 文档的 tokenizer 版本。
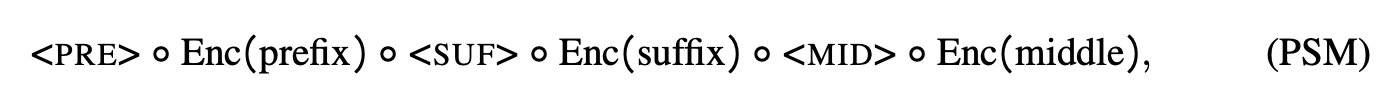
其中 表示连接。不同的文档(无论是 FIM 还是 AR)随后会通过 连接起来,并在训练期间输入到模型中。我们重申,我们保留了前缀、中间和后缀三个部分的损失,因此 FIM 训练不会导致自回归学习信号的下降。初步实验(虽然本文未报告)表明,这种选择对于 FIM-for-free 属性的保持至关重要。无论 token 是否被屏蔽,此属性都不会改变;但是,始终在 token 上进行训练非常重要,因为它表示已成功连接到后缀。
为了进行推理,我们对给定的前缀和后缀进行编码,并使用
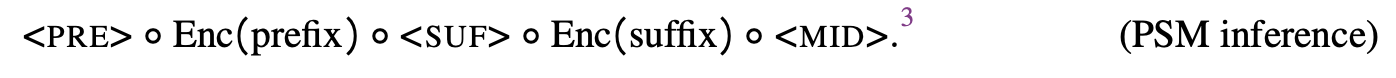 我们继续从模型中采样,直到它生成 token,这是模型传达它已连接前缀和后缀的方式。
我们继续从模型中采样,直到它生成 token,这是模型传达它已连接前缀和后缀的方式。
如果模型未能在合理分配的推理 token 预算内生成 token,这通常表明模型在连接前缀和后缀时遇到了困难,并且生成的样本通常质量较差,这促使我们采用 EOT 感知的 best-of-n 采样方法。更多讨论请参阅附录 H。
3.1 SPM mode

我们还引入了上述过程的变体,其中我们交换前缀和后缀的顺序,称为 SPM,以强调顺序变为后缀、前缀和中间。引入 SPM 的主要动机是改进推理过程中的 key-value 缓存。这一优势的原因是,使用 SPM,将 token 附加到前缀不再会使后缀部分中计算的 key 和 value 失效。请注意,SPM 缓存的优势并非普遍适用,可能取决于应用程序。特别是在 SPM 模式下,对后缀的微小更改会导致前缀的缓存失效,但我们预计在实际工作负载中对后缀的更改比对前缀的更改要少。有趣的是,我们在第 4.3 节中发现,除了缓存优势之外,SPM 在填充基准测试中实际上也略胜 PSM。
在我们的主要运行中,我们分别在 PSM 模式和 SPM 模式下分别以 50% 的概率应用 FIM 变换,因此模型能够在推理中处理这两种格式。换句话说,每种模式都继承了总 FIM rate p 的一半。我们取消了这种在 PSM 和 SPM 上联合训练的选择,并与纯 PSM 和 SPM 运行进行了比较。表 1 中的结果显示了这种选择的有效性。
尽管 SPM 模式的理念很简单,但在 SPM 中特殊 token 的放置有一些微妙之处,这在 SPM 和 PSM 联合训练时尤为重要。我们将在附录 D 中介绍这些细节。
3.2 Context-level FIM
在语言模型训练中,文档通常使用边界 token(称为 )进行连接,然后根据模型上下文长度进行分块。将 FIM 应用于长文档时,此操作可能会导致 FIM 数据碎片化,其中整个前缀或后缀可能会在分块过程中从上下文中被截断。为了解决这个问题,我们可以在分块步骤之后应用 FIM。一个上下文切片可能包含多个文档,这些文档通过 边界 token 进行连接。因此,我们根据 进行拆分,将部分文档转换为 FIM 示例,其概率由 FIM rate 给出,然后再使用 连接这些示例。然后将生成的切片修剪为模型上下文长度。有关 FIM 转换的更多详细信息,请参阅附录 C。在 4.4 节中,我们展示了此技术如何提升相对于文档级 FIM 的性能,并在本研究的所有主要 FIM 运行中都采用了上下文级 FIM。